Crear aplicaciones de IA generativa resistentes, iniciar tu transformación de IA, migrar a la nube y mucho más.
Entrena a rus LLM para que adquieran capacidades avanzadas de razonamiento y codificación con datos humanos propios de alta calidad.
Amplía tu equipo de ingeniería de software interno con nuestro personal seleccionado.
Trabajo de Ingeniero de datos Remoto
En Turing, estamos buscando ingenieros de datos capacitados que puedan construir infraestructuras de procesamiento de datos e informes que impulsen las ideas y la inteligencia técnica de toda la empresa. Forma parte del 1% de los mejores ingenieros de datos y aprende al lado de los mejores.
Descubre trabajos remotos en software con centenas de clientes de Turing
Descripción del puesto
Responsabilidades del puesto
- Diseñar pipelines/ETL y bases de datos utilizando tecnologías de vanguardia y herramientas.
- Liderar el equipo para desarrollar soluciones analíticas operativamente eficientes.
- Definir estándares y metodologías para el ambiente de Data Warehouse.
- Diseñar y construir pipelines de datos altamente escalables utilizando las últimas herramientas y tecnologías como AWS, Snowflake, Spark y Kafka para incorporar datos desde varios sistemas.
- Convertir las necesidades complejas del negocio en soluciones técnicas escalables de acuerdo a los estándares del Data Warehouse.
- Crear pipelines de datos escalables y aplicaciones ETL que respalden las operaciones de negocios en publicidad, contenido y finanzas/contaduría.
- Asistir con los problemas que surjan en el descifrado de la migración de datos y con las mejoras del desempeño del sistema.
- Colaborar eficazmente con los gerentes de producto, gerentes de programas técnicos, operaciones y otros ingenieros.
Requisitos mínimos
- Licenciatura/Master/Doctorado en Informática o campo relevante.
- Amplia experiencia en construir sistemas de datos escalables y productos basados en datos trabajando con equipos interdisciplinarios.
- +2 años de experiencia en Ingeniería de software/de datos relacionada con dominio de Python.
- Habilidad para crear pipelines de datos y aplicaciones ETL con conjuntos de datos voluminosos.
- Competencia en construir REST APIs para servicios back-end.
- Experiencia en la administración de SQL DB (PostgreSQL, MS SQL, etc.)
- Exposición a implementación, testeo, depuración e implementación de pipelines de datos utilizando cualquiera de las siguiente herramientas: Prefect, Airflow, Glue, Kafka, Serverless(Lambda, Kinesis, SQS, SNS), Fivetran, o Stitch Data/Singer.
- Experiencia en cualquiera de las tecnologías Data Warehouse de la nube: Redshift, BigQuery, Spark, Snowflake, Presto, Athena, S3.
Habilidades preferidas
- Comprensión de arquitecturas web complejas, distribuidas y de microservicio.
- Experiencia en Python en back-end, ETL para trasladar de una base de datos hacia otra.
- Buena comprensión de las necesidades analíticas y proactividad para construir soluciones genéricas que aumenten la eficacia.
¿Interesado en este trabajo?
Aplica a Turing hoy mismo.
¿Por qué unirse a Turing?

1Empleos de élite en EE. UU.

2Crecimiento profesional

3Asistencia al Desarrollador







¿Cómo convertirse en un desarrollador de Turing?
Crea tu perfil
Completa tus datos básicos: nombre, ubicación, conocimientos, expectativa salarial y experiencia.
Realiza nuestras pruebasy entrevistas
Resuelve pruebas y asiste a una entrevista técnica.
Recibe ofertas de trabajo
Las mejores empresas de EE.UU. y Silicon Valley te elegirán como colaborador.
Obtén el trabajo de tus sueños
Una vez que seas parte de Turing, ya no tendrás que volver a buscar otro trabajo.

¿Cómo convertirse en Ingeniero de datos?
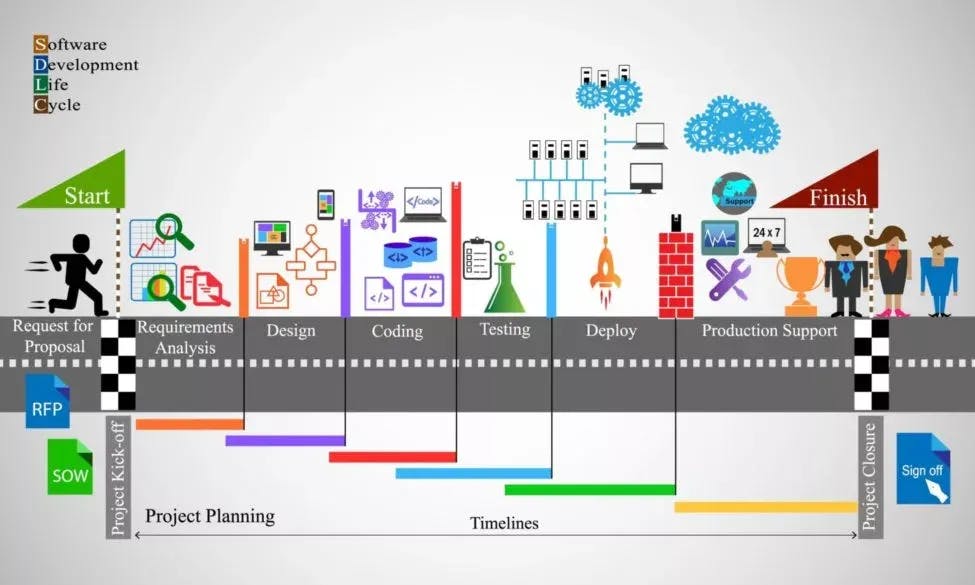
La ingeniería de datos abarca una variedad de títulos, con un enfoque central en la construcción de infraestructuras confiables para permitir un flujo de datos constante en un entorno orientado a datos. Estos ingenieros son facilitadores de datos limpios y brutos de distintas fuentes para que las personas los utilicen en la toma de decisiones dentro de la empresa.
La ingeniería de datos es el proceso de desarrollo y construcción de sistemas de recogida, almacenamiento y análisis de datos a gran escala. Es un campo muy amplio con aplicaciones en casi todos los sectores. Las organizaciones pueden recopilar grandes volúmenes de datos, pero necesitan el personal y la tecnología adecuados para garantizar que los datos tengan una forma útil cuando lleguen a los científicos y analistas de datos.
¿Qué hace un ingeniero de datos?
Los ingenieros de datos diseñan sistemas que recopilan, manejan y convierten los datos en bruto en información utilizable para que los científicos de datos y los analistas empresariales la comprendan en una serie de escenarios. El objetivo final es hacer que los datos estén más disponibles para que las empresas puedan evaluar y mejorar su rendimiento.
¿Cuál es el alcance de un Ingeniero de datos?
El trabajo remoto de un ingeniero de datos es uno de los más demandados por las empresas. Son muy valorados en todos los ámbitos y reciben una buena remuneración por su trabajo.
La demanda de trabajos relacionados con los datos crece día a día a medida que cada vez más empresas incursionan en la Big Data y explotan los datos para obtener información útil. Los ingenieros en datos no son la excepción. Las empresas siempre están buscando ingenieros de datos competentes capaces de trabajar con una gran cantidad de volumen de datos complejos para generar conocimientos empresariales útiles. Y, como el trabajo requiere un alto grado de experiencia y competencia en Big Data, el potencial de ingresos de los ingenieros de datos también ha aumentado.
¿Cuáles son las funciones y responsabilidades de los Ingenieros de datos?
La principal responsabilidad de un ingeniero de datos es conceptualizar y construir una infraestructura fiable para traducir los datos en formas que los científicos de datos puedan entender. Los ingenieros de datos remotos deben ser capaces de identificar tendencias en conjuntos de datos masivos, además de diseñar procesos escalables para transformar datos semiestructurados y no estructurados en representaciones utilizables. Los ingenieros de datos esencialmente preparan y transforman los datos en bruto para que puedan ser utilizados con fines analíticos y operativos.
Ahora, ¿Cuál es la función de un ingeniero de datos? veamos las responsabilidades de sus puestos de trabajo:
- Desarrollar, construir, probar y mantener arquitecturas
- Ensamblar grandes conjuntos de datos y complejos que se ajusten a los requisitos del negocio.
- Implementar programas de análisis sofisticados, machine learning y métodos estadísticos-
- Seguridad y gobernanza de datos con controles de seguridad modernos.
- Traducir necesidades funcionales y técnicas complejas en diseños elaborados.
- Almacenamiento de datos con tecnologías como Hadoop, NoSQL, etc.
- Encontrar patrones ocultos a partir de trozos de datos, creando modelos.
- Integración de los procesos de gestión de datos en la estructura actual de la organización.
- Ayudar en la integración fluida de terceros y desarrollar una infraestructura robusta.
- Crear servicios web de alto rendimiento y escalables para el seguimiento de los datos.
¿Cómo convertirse en Ingeniero de datos?
Puedes empezar una carrera profesional de ingeniería de datos si tienes la combinación correcta de habilidades y conocimientos. Una licenciatura en informática o en campos similares es bastante común entre los ingenieros de datos. Estudiando una licenciatura, puedes sentar las bases de los conocimientos en este sector. También puedes cursar un máster para mejorar tu carrera y acceder a oportunidades probablemente mejor remuneradas.
Los ingenieros de datos suelen tener una formación en informática, ingeniería, matemáticas aplicadas o campos relacionados a IT. Dado que el trabajo requiere un alto nivel de conocimientos técnicos, puede que un bootcamp o una certificación no sean suficientes para los futuros ingenieros de datos.
Necesitarás conocimientos de programación en diversos lenguajes, como Python y Java, así como conocimientos de arquitectura de bases de datos SQL. Si ya tienes experiencia en IT o en campos relacionados como matemática o analítica, un bootcamp o una certificación podrían ayudarte a diseñar un CV para obtener un trabajo remoto de ingeniería de datos.
Si no tienes experiencia en tecnología o informática, puede que tengas que inscribirte en un programa más intensivo para poder demostrar tus conocimientos en la materia. Es posible que tengas que tener un título universitario. Si tienes una licenciatura pero no es en un campo relevante, sigue investigando los másters en análisis e ingeniería de datos.
Dedica algo de tiempo a mirar las ofertas de trabajo para descubrir lo que buscan los empleadores y comprender cómo encaja tu experiencia en ese rol.
¿Estás interesado en trabajos remotos de Ingeniero de datos?
¡Conviértete en un desarrollador de Turing!
Habilidades necesarias para convertirse en un Ingeniero de datos
1. Hadoop y Spark
La librería de software Apache Hadoop es un framework de trabajo que utiliza principios básicos de programación para permitir el procesamiento distribuido de volúmenes masivos de datos en clusters de máquinas. Está construido para expandirse desde un único servidor hasta miles de dispositivos, cada uno con sus capacidades de computación y almacenamiento. Python, Scala, Java y R son algunos de los lenguajes de programación que admite el framework. Aunque Hadoop es la herramienta más potente para los grandes volúmenes de datos, tiene varias limitaciones, como la lentitud de procesamiento y un alto nivel de codificación. Apache Spark es un motor de procesamiento de datos que permite el procesamiento de flujos y que implica la entrada y salida continua de datos. Es similar a Hadoop ya que realiza muchas de las mismas actividades.
2. C++
Cuando no se tiene un algoritmo predeterminado, C++ es un lenguaje de programación muy básico pero potente para calcular rápidamente conjuntos de datos masivos. Es el único lenguaje de programación que puede manejar más de 1GB de datos en solo un segundo. También puede volver a entrenar los datos y utilizar el análisis predictivo en tiempo real, manteniendo la consistencia del sistema de registro.
3. Almacen de datos
Un almacén de datos es una base de datos relacional para consultar y analizar datos. Su objetivo es brindar una imagen a largo plazo de los datos a través del tiempo. Una base de datos, en cambio, actualiza continuamente los datos en tiempo real. Los sistemas de almacenamiento de datos más populares, como Amazon Web Services y Amazon Redshift, deben ser reconocidos por los ingenieros de datos. AWS es un requisito previo en casi todos los requisitos de trabajo de los ingenieros de datos.
4. Azure
Azure es una plataforma en la nube de Microsoft que permite a los ingenieros de datos crear soluciones de análisis de datos a gran escala. Con una solución de analítica empaquetada fácil de implementar, simplifica la implementación y el soporte de servidores y aplicaciones. El paquete incluye servicios preconstruidos para todo, desde el almacenamiento de datos hasta el potente machine learning. Azure es tan popular que algunos ingenieros de datos se especializan en él.
5. SQL Y NoSQL
El lenguaje de programación SQL es el estándar de la industria para crear y mantener sistemas de bases de datos relacionales (tablas que constan de filas y columnas). Las bases de datos NoSQL no tabulares existen en varias formas y tamaños, dependiendo de sus modelos de datos, como un gráfico o un texto. Los sistemas de gestión de bases de datos (DBMS) son una aplicación de software que ofrece una interfaz a las bases de datos para el almacenamiento y la recuperación de información, que son conocimientos necesarios para los ingenieros de datos.
6. Machine Learning
Los científicos de datos utilizan algoritmos de machine learning, a menudo conocidos como modelos, para crear predicciones basadas en datos actuales y pasados. Los ingenieros de datos requieren simplemente una comprensión básica del machine learning para comprender mejor las necesidades de los científicos de datos (y, por extensión, las necesidades de la empresa), implementar modelos y construir tuberías de datos más precisas.
7. API de datos
Una API es una interfaz de acceso a datos para aplicaciones de software. Permite que dos aplicaciones o dispositivos interactúen entre sí para completar un determinado trabajo. Las aplicaciones web, por ejemplo, emplean la API para interactuar entre el front-end orientado al usuario y la funcionalidad y los datos del back-end. Una API permite que una aplicación lea una base de datos, obtenga información de las tablas pertinentes de la base de datos, procese la solicitud y entregue una respuesta basada en HTTP a la plantilla web, que luego se muestra en el navegador web. Para que los científicos de datos y los analistas de inteligencia empresarial puedan consultar los datos, los ingenieros de datos proporcionan API en las bases de datos.
8. Extraer, transferir, cargar (ETL)
ETL (Extract, Transfer, Load) es el proceso de extraer datos de una fuente, convertirlos en un formato que pueda ser analizado y guardarlos en un almacén de datos. El procesamiento por lotes se utiliza en este procedimiento para ayudar a los usuarios a analizar los datos relevantes para un reto empresarial concreto. El ETL recopila datos de diversas fuentes, aplica reglas de negocio a los datos y, a continuación, carga los datos transformados en una base de datos o en una plataforma de inteligencia empresarial, donde todos los miembros de la empresa pueden acceder a ellos y utilizarlos.
¿Estás interesado en trabajos remotos de Ingeniero de datos?
¡Conviértete en un desarrollador de Turing!
¿Cómo conseguir trabajos remotos de Ingeniero de datos?
Convertirse en desarrollador es muy gratificante. Sin embargo, es necesario tener un gran conocimiento de los lenguajes de programación, y es recomendado practicar hasta conseguirlo. Además, tener una visión del producto también es fundamental para estar en sintonía con el equipo. Las buenas habilidades de comunicación ayudan a colaborar con los miembros del equipo y a priorizar el trabajo de acuerdo al plan a largo plazo.
Para ayudarte en la búsqueda de trabajo de ingeniero de datos remoto, Turing te facilita las cosas y ofrece los mejores puestos de trabajo remoto que se adaptan al crecimiento de tu carrera profesional. Únete a la red de los mejores desarrolladores del mundo y consigue trabajos remotos de ingeniero de datos full-time y a largo plazo con un mejor salario y crecimiento profesional.
¿Por qué convertirte en ingeniero de datos en Turing?
Empleos de élite en EE.UU.
Oportunidades a largo plazo para trabajar en grandes empresas estadounidenses, orientadas a un objetivo y con una gran compensación.
Crecimiento profesional
Trabaja en problemas técnicos y empresariales desafiantes utilizando tecnología de vanguardia para acelerar el crecimiento de tu carrera.
Comunidad exclusiva de desarrolladores
Únete a una comunidad mundial de desarrolladores de software de élite.
Una vez que te unas a Turing, nunca más tendrás que buscar otro trabajo
Los compromisos de Turing son a largo plazo y a tiempo completo. Cuando un proyecto llega a su fin, nuestro equipo se pone a trabajar para identificar el siguiente en cuestión de semanas.
Trabaja desde la comodidad de tu casa
Turing te permite trabajar según tu conveniencia. Tenemos un horario flexible y puedes trabajar para las mejores empresas de Estados Unidos desde la comodidad de tu casa.
Gran compensación
Al trabajar con las principales empresas de EE.UU., los desarrolladores de Turing ganan más que el salario estándar del mercado en la mayoría de los países.
¿Cuánto le paga Turing a los Ingenieros de datos?
Turing te ayuda a sugerir un rango salarial que te permita encontrar una buena oportunidad a largo plazo. La mayoría de nuestras recomendaciones se basan en el análisis de las condiciones actuales del mercado y las demandas de nuestros clientes. Sin embargo, en Turing creemos en la flexibilidad. Por lo tanto, cada ingeniero de datos puede fijar su rango salarial de acuerdo a sus habilidades y experiencia.
Preguntas Frecuentes
Últimas entradas de Turing







Liderazgo
Política de Igualdad de Oportunidades
Explora trabajos remotos de desarrollador

Basadas en tus conocimientos
- React/Node
- React.js
- Node.js
- AWS
- JavaScript

- Python

- TypeScript

- Python/React

- Java
- PostgreSQL

- React Native
- PHP
- PHP/Laravel

- Golang
- Ruby on Rails

- Angular
- Android

- iOS

- ASP.NET

Basadas en tu rol
+ Ver más rolesBasadas en tu trayectoria profesional
- Desarrollador de Software
- Desarrollador de Software Senior
- Ingeniero de Software
- Ingeniero de Software Senior
- Desarrollador Senior Full-stack
- Desarrollador Senior Front-end
- Ingeniero Senior de DevOps
- Desarrollador Java Senior
- Líder Técnico de Software Senior