How to Create Naive Bayes Document Classification in Python?
•6 min read
- Languages, frameworks, tools, and trends

The Naive Bayes text classification algorithm is a type of probabilistic model used in machine learning. Harry R. Felson and Robert M. Maxwell designed the first text classification method to classify text documents with zero or more words from the document being classified as authorship or genre.
Since then, Naive Bayes has become one of the most popular and effective classification methods for unsupervised learning of data. This article is an introduction to creating a simple Naive Bayes document classification system in python.
Naive Bayes is a probability-based machine learning algorithm that uses Bayes' theorem with the assumption of “naive” independence between the variables (features), making it effective for small datasets. The Naive Bayes algorithms are most useful for classification problems and predictive modeling.
What is the Naive Bayes classification?
An algorithm based on Naive Bayes is a probabilistic classification algorithm. Based on strong independent assumptions, it uses probability models. There is often no impact on reality due to independent assumptions. As a result, they are considered naive.
Bayes' theorem can provide probability models (credited to Thomas Bayes). It is possible to train the Naive Bayes algorithm in supervised learning, depending on the nature of the probability model.
Naive Bayes models consist of a large cube with the following dimensions:
- Name of the input field.
- Depending on the input field type, the value range can be continuous or discrete. By using a Naive Bayes algorithm, continuous fields get divided into discrete bins.
- Value of the target field.
The Naive Bayes algorithm
Bayes theorem
Let’s say you defined a hypothesis regarding your data.
The theorem will state the chances that the hypothesis will occur to be true by multiplying the probable chances. This way the hypothesis will occur true given certain scenarios.
It further divides the product by the probability that the defined scenario will show.
Because we are classifying documents, the hypothesis is that the document belongs to Categorical C. The evidence is the occurrence of the word W.
We can use the ratio form of the Bayes theorem in classification tasks because we are comparing two or more hypotheses, which involves comparing the numerators within the formula (for Bayes aficionados: the prior times the likelihood) for each hypothesis:
Due to a large number of words in a document, the formula becomes:
The Naive Bayes classifier can be used in the following applications:
- Emails are automatically classified into folders, including: "Family", "Friends", "Updating", and "Promotions".
- Job listings are automatically tagged. Job listings in raw text format can get classified according to keywords: "software development", "design", and "marketing".
- Products automatically get categorized. We can classify the products according to their description, such as books, electronics, clothing, etc.

Often, even very sophisticated classification methods, especially those utilizing very large datasets, do not perform as Naive Bayes. This is mainly because Naive Bayes is very simple.
Pros and cons of Naive Bayes
Pros
- This algorithm is fast and easy to use and helps in predicting the class of a dataset very quickly.
- You can easily solve multiclass prediction problems as it's quite useful.
- As compared to other models with independent features, the Naive Bayes classifier performs better with less training data.
- The Naive Bayes algorithm performs exceptionally well with categorical input variables.
- Using this method, you can predict the class of test data easily and quickly. It also performs well when predicting multiple classes at once.
- When the assumption of independence is true, Naive Bayes classifiers outperform logistic regression.
- For categorical variables, it performs well compared to numerical input variables. When dealing with numerical input variables, the bell curve is assumed.
Cons
- It is impossible for the Naive Bayes model to make any predictions if your test data set contains a categorical variable that was not present in your training data set. A smoothing technique known as Zero Frequency can solve this problem.
- In addition to being a lousy estimation algorithm, 'predict_proba' also computes probability outputs.
- While in theory, it sounds great, you'll not find many independent features in real life.
- Consequently, the model fails to predict if it assigns a zero (zero) probability to the categorical variable (in the test data set) that it did not observe in the training data set. In this case, we are dealing with "Zero Frequency". This is accomplished by using Laplace estimation, one of the simplest smoothing techniques.
- Alternatively, Naive Bayes is a poor estimator, so we shouldn't take too much advantage of the results from predict_proba.
- Naive Bayes suffers from another limitation in that it assumes independent predictors. In reality, independent predictors are almost impossible to obtain in practice.
Naive Bayes assumption
Assuming that each word is independent of all the others will help us with the equation and, ultimately, with creating codes.
To simplify the math, we can make this assumption, which, in practice, works quite well. Knowing which words come before/after has a direct impact on the next/previous word.
Naive Bayes is based on this assumption. Based on that assumption, we can decompose the numerator as follows.
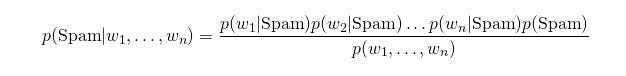
When to use Naive Bayes
A Naive Bayesian classifier performs worse than a complex classifier due to the strict assumptions it makes about the data. The classifier, however, has some advantages:
- Training and predicting the model is done at a high speed.
- Probabilistic predictions can be created purely based on the data.
- They are usually pretty easy to interpret.
- Their parameters are usually not tunable.
An initial baseline classifier based on a Naive Bayesian classifier offers these advantages. In case it performs well, you will have a classifier for your problem that is intuitive and very fast to interpret.
With some basic knowledge of how well they should perform, you can explore more sophisticated models if it does not perform well initially
How to execute Naive Bayes in Python
Let's get started and upload the libraries first:
We will now load the data (training and test data):
Let's count the classes and samples:
You will get output as:
As a result, we have a 20-class (which is the by default no. of classes in which the algorithm divides the data) text classification problem with a training sample size of 11314 and a test sample size of 7532 (text sentences).
Let's take a look at the third training sample:
You should see something like this printed out since our data is texts (specifical emails):
Outputs
Next, we will build a Naive Bayes classifier and train it. Our example will generate a matrix of token counts based on a collection of text documents. To do so, we will use the make_pipeline function.
We can predict the labels of the test set in the las line of the code.
Here are the predicted category names:
Let's construct a multi-class confusion matrix to check if the model is suitable or if it only predicts certain text types correctly.
Naive Bayes is a powerful machine learning algorithm that you can use in Python to create your own spam filters and text classifiers. Naive Bayes classifiers are simple and robust probabilistic classifiers that are particularly useful for text classification tasks. The Naive Bayes algorithm relies on an assumption of conditional independence of features given a class, which is often a good first approximation to real-world phenomena.
Naive Bayes is becoming a popular text classification technique that can quickly provide a somewhat accurate "guess" as to the category of a document. It is a probabilistic classifier and can give very impressive results. It also scales nicely, allowing you to process thousands of documents. Its ability to keep up with new words makes it more accurate in predicting categories than other popular methods.

Author
Sanskriti Singh
Sanskriti is a tech writer and a freelance data scientist. She has rich experience into writing technical content and also finds interest in writing content related to mental health, productivity and self improvement.