
Data Science
Basic Interview Q&A

1. What does the term Data Science mean?
Data Science is an interdisciplinary field that uses scientific methods, algorithms and systems to extract knowledge and insights from structured and unstructured data. It combines the principles and practices from a variety of fields such as mathematics, statistics, computer engineering and more.
The data science life cycle looks something like this:
- First, the problem is defined and the data needed for the problem is outlined.
- After that, the necessary data is collected through various sources.
- Then, the raw data collected is cleaned for inconsistencies and missing values.
- After that, the data is explored and a summary of the insights is collected.
- The cleansed data is then run through different algorithms such as text mining, recognition patterns, predictive analytics, etc.
- Finally, reports, charts, graphs, and other visualization techniques are used to present the results to the business stakeholders
2. Is there any difference between data science and data analytics?
Data science uses various tools and techniques including data analytics to gather meaningful insights and present them to business stakeholders. On the other hand, data analytics is one of the techniques that analyzes raw data to determine trends and patterns. These trends and patterns can help guide businesses in making effective and efficient decisions. Data analytics uses historical and present data to understand current trends. Whereas, data science uses predictive analytics to determine future problems and drive innovations. Answering this data science interview question can distinguish you from the rookies.
3. Mention some techniques used for sampling and their main advantages.
Sampling is at the core of data science and hence, this data science interview question gives you the opportunity to display your core knowledge. When the data set is very large in size, it is not feasible to conduct an analysis on the entire data set. In such cases, it is critical to select a sample from the given population and conduct data analytics on the selected dataset. This requires caution as a representative sample that represents the true characteristics of the entire population must be selected. The two main sampling techniques used as per statistical needs are:
- Probability samplings such as cluster sampling, random sampling, and stratified sampling
- Non-probability samplings such as quota sampling, convenience sampling, and snowball sampling
4. Outline the differences between supervised and unsupervised learning.
This is an important data science statistics interview question. Let’s outline the differences:

5. Mention the conditions for underfitting and overfitting.
Underfitting: Underfitting means that the statistical model does not fit the existing data set. Underfitting occurs when less training data is provided. The statistical model in underfitting is extremely weak in identifying the relationship in the data and thus, unable to identify any underlying trends. Underfitting can ruin the accuracy of the machine learning model. It can be avoided if more data is used and the number of features is reduced by using feature selection.
Overfitting: A statistical model is overfitted when a lot of data is used to train it. When too much data is used the model learns from the noise and inaccurate data as well, resulting in the inability of the model to categorize the data accurately. Overfitting occurs when non-parametric and non-linear methods are used. Solutions include using a linear algorithm and using parameters such as maximal depth.
Sometimes simple data science interview questions like the above can catch you off-guard, make sure you are prepared with such questions.
6. What is imbalanced data?
When there is an unequal distribution of data across categories, the data is said to be imbalanced. Imbalanced data produces inaccurate results and model performance errors. Additionally, when training a model using an imbalanced dataset, the model pays more attention to the highly populated classes and poorly identifies the less populated classes.
7. Which language is more popular for data science?
Python is the most popular language for data science, followed by R. This is so because Python provides great functionality for statistics, mathematics and scientific functions. Further, it offers rich libraries for data science applications.
8. What are the three types of big data?
Structured, semi-structured, and unstructured data are the three types of data in big data.
9. What is supervised learning?
Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset, either to classify data or predict outcomes.
10. Name five V’s of big data?
Volume, Velocity, Variety, Veracity, and Value are the five V’s of big data.
11. Can we process raw data more than once?
Raw data can be processed more than once. This is often done to clean or transform the data.
12. What type of database is MongoDB?
MongoDB is a form of a NoSQL database.
13. Define Enumeration.
Enumeration is a process of assigning a numerical value to each member of a set or group. This can be used to count things or to identify members of a group.
14. Is MICE a data imputation package?
MICE is a data imputation package, which can be used to fill in missing values in data.
15. What is an Outlier?
Outliers are values that deviate significantly from the rest of the data and are sometimes caused by errors.
16. Which language does relational database use?
Relational databases use a language called SQL (Structured Query Language) that is useful in manipulating data in the database.
17. Which one is better for text analytics: R or Python?
Python would be best suited for text analytics because of rich libraries like Pandas.
18. What does the P value greater than 0.5 indicate?
A P-value greater than 0.5 indicates that the null hypothesis is more likely true than the alternative hypothesis.
19. Is Tuple an immutable data structure?
Yes, a tuple is an immutable data structure, which means that once it is created, it cannot be modified.
20. How many expressions does a lambda function have?
A lambda function has only one expression.
21. What is NLP?
NLP stands for Natural Language Processing, which is a process of extracting information from text data.
22. Define disaggregation of data.
Disaggregation of data is the process of breaking down data into smaller, more manageable pieces.
23. How to normalize variables?
To normalize variables, you need to standardize the data so that each variable has a mean of 0 and a standard deviation of 1.
24. What is deep learning?
Deep learning is a subset of machine learning that that enables machines to learn from experience and understand the world in terms of a hierarchy of concepts. Deep learning can be used to build intelligent systems that can make decisions and predictions based on data.
25. What is vertical representation of data called?
The vertical representation of data is known as column, while the horizontal representation of data is known as rows.
26. What is the meaning of K in K-mean algorithm?
The "K" in K-means algorithm stands for the number of clusters that the algorithm will form. K-means is an unsupervised learning algorithm that clusters data into K distinct clusters.

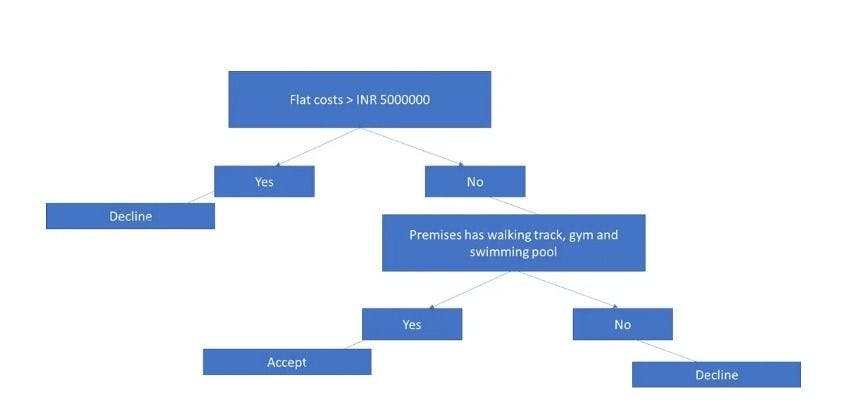

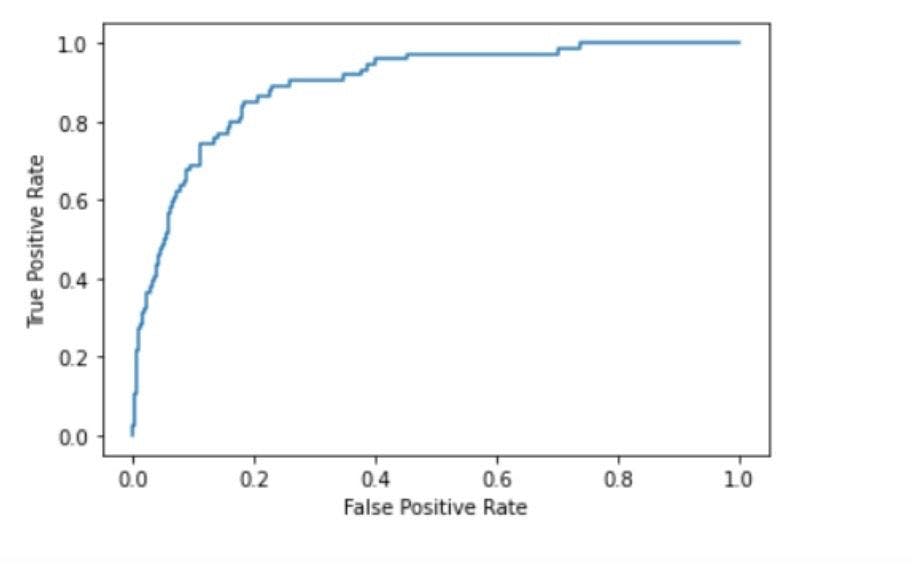
Wrapping up
This extensive list of data science interview questions is designed to cater to the needs of both developers and technical recruiters. These interview questions test developers on different topics, including mathematics, statistics, programming, ML, etc. Whether you are a fresher or a developer who is looking for a job change, these data science interview questions and answers will help you prepare for the job. For hiring managers, these questions can serve as a reference to assess the proficiency of Data Scientists.
Hire Silicon Valley-caliber Data Science developers at half the cost
Turing helps companies match with top quality remote JavaScript developers from across the world in a matter of days. Scale your engineering team with pre-vetted JavaScript developers at the push of a buttton.
Tired of interviewing candidates to find the best developers?
Hire top vetted developers within 4 days.





Leading enterprises, startups, and more have trusted Turing

Check out more interview questions
Hire remote developers
Tell us the skills you need and we'll find the best developer for you in days, not weeks.